Sub-Queries are evaluated by the SQL optimizer. It is normal that a sub- query
is evaluated ONCE and then the result is passed to the outer query.
A Problem: With the MUSIC database, get the system to list all artists
along with the name of their most recent album
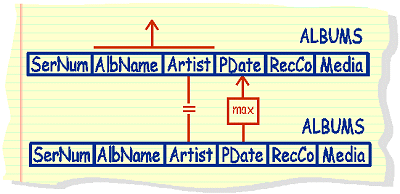
NOTE the existence of BOTH a join condition and a subquery.
select alb_name, artist, p_date
from albums A
where p_date in
(select max(p_date)
from albums
where artist = A.artist)
NOTE: there is an explicit reference to an outer query column. Whenever
a sub-query 'reaches out' to the outer query, the sql optimizer is forced
to RE-EVALUATE the subquery for each row of the outer query. This takes
time and can rapidly increase processing time - should be avoided UNLESS
THERE IS NO OTHER WAY
alternate mSQL:
select alb_name, artist, max(p_date)
from albums
group by artist
Correlation with large tables VASTLY increases processing and retrieval
time, even if compared with a non-correlated query that does the same
job but takes longer to write. We should use group by, join or temporary
tables to avoid correlation if possible.
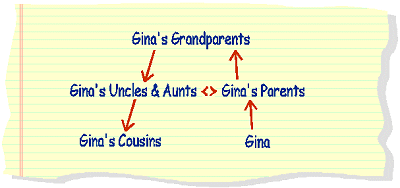
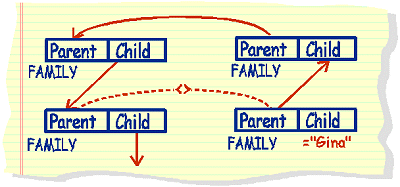
Correlation example 2: People who are cousins of Gina.
select person
from family <--- people with parents that are children of gina's grandparents
where parent in
(select person
from family <--- parents with gina's grandparents as parents
where parent in
(select parent
from family <--- gina's grandparents
where person in
(select person
from family <--- gina's parents
where person = 'gina')))
this query will result in an answer table that contains GINA, and her
brothers and sisters, along with her cousins
a correlated revision of the above query....
select person
from family A <--- people with parents that are child of gina's grandparents
where parent in
(select person
from family <--- parents with gina's grandparents as parents
where parent in
(select parent
from family <--- gina's grandparents
where person in
(select person
from family <--- gina's parents
where person = 'gina'
and parent ^= A.parent)))
This query is very processor intensive, and takes a significant time
on a slow processor.
An Alternative Formulation..... Gina's cousin revisited
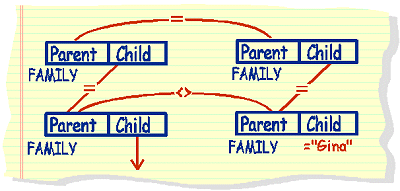
select distinct person
from family A, family B, family C, family D
where a.parent = b.person
and b.parent = d.parent
and c.parent = d.parent
and c.parent ^= a.parent
and a.person = 'gina'
This executes faster than the correlated solution even though it is
a 4 table join.
EXISTS OPERATOR
Question:list the total number of artist names that have albums with
track listings (i.e. songs in the tracks table)
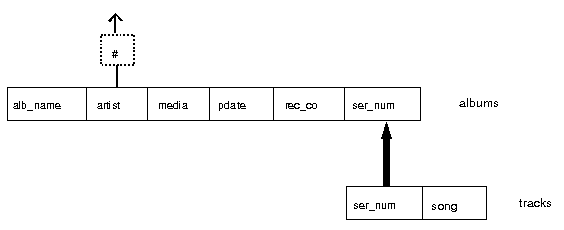
select count(artist)
from albums
where ser_num in
(select ser_num
from tracks)

select albname, artist
fom albums A
where exists
(select *
from tracks
where ser_num = A.ser_num)
The EXISTS operator is used to test if there is at least one row in
the sub- query table that matches the outer query condition. If there
is, then the outer query is evaluated.
NOT EXISTS is also available.
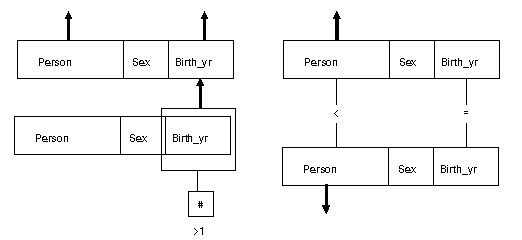
CORRELATION - a final example...
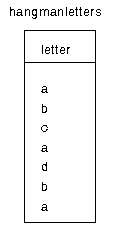
In the table, you are required to produce a list of those letters
that are duplicated..
select letter
from hangmanletters
group by letter
having count(letter) > 1
NOW write a query that deletes from the table all duplicates from
the table.
delete from hangmanletters
where letter in
(select letter
from hangmanletters
group by letter
having count > 1)
results in....the wrong answer
This can be explained by the fact that the subquery is evaluated only
once, and therefore those found to be duplicated in the table are deleted
(every occurrence of them)
solution:
delete from hangmanletters H
where letter in
(select letter
from hangmanletters
where letter = H.letter
group by letter
having count(letter) > 1)
NOTE the correlation